Understanding Speech Recognition: A Hands-On Guide to Phoneme Classification
Every voice assistant you’ve used—like Siri or Alexa—works by breaking speech into its basic sound units, called phonemes. In this article, I’ll share my learnings in tackling phoneme classification.

What You’ll Learn: Building, Training, and Optimizing a Speech Recognition Pipeline
I’ll guide you through the process of building a speech recognition pipeline—from processing raw audio to training a deep learning model. Along the way, I’ll discuss some of the challenges I faced in this process and how I overcame them. By the end, you should have a clearer picture of how to approach phoneme classification yourself.
My focus was on classifying 25ms audio segments into 71 distinct phonemes, including silence and unknown sounds as outlined here. This step is crucial for converting speech to text and forms the backbone of modern speech recognition systems.
The Challenge
Building a robust phoneme classifier includes a few challenges that often need to be addressed:
Phonemes don't fit neatly into single frames: They often stretch across multiple time segments.
Variability in speech: Some sounds are far more common than others in natural speech.
Every speaker sounds different: Accents, speaking styles, and background noise all complicate the task.
Processing the Audio
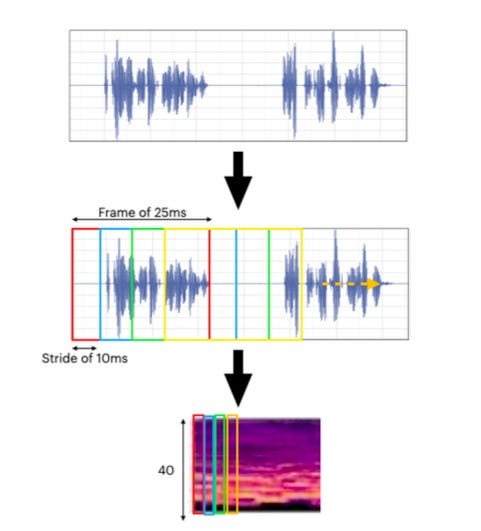
Converting to Mel-Spectrograms
Raw audio is split into overlapping 25ms frames, moving forward (stride) 10ms at a time
Each chunk is run through a Fourier Transform
Mel-scale filters are applied to match human hearing perception
This results in 40 features that capture the key acoustic properties of each frame

Adding Context is Crucial
By including k = 42 frames before and after our target frame (about 875 milli-seconds total), my training model gets crucial context about the surrounding speech.
This expanded each input from 40 features to 3,400 (85 frames × 40 features)
This visual below illustrates a target frame with a context k=3 (3*2 + 1 = 7 frames)

Dataset Overview
Here’s a quick look of the resulting dataset:
Training: 14,542 utterances (18,482,968 frames)
Validation: 2,200 utterances (1,559,057 frames)
Testing: 2,200 utterances (1,618,835 frames)
After preprocessing, the frame shape was torch.Size([3400]).
Each audio clip or utterance has a num_freqs dimension of size 40. The length num_frames varies between audio clips, with some being longer than others.
In summary, each audio clip is represented as a 2-dimensional array (num_frames × 40 features, which expands to 3,400 features with context). The training dataset comprises over 14,500 utterances, totaling approximately 18 million frames.

Handling Large-Scale Data
Processing 18 million+ training frames efficiently was a resource bottleneck. Here's how I addressed it. I utilized PyTorch’s Dataset (custom implementation with KContextSpectrograms) and DataLoader utilities to streamline this process, ensuring memory and compute efficiency.
Memory Usage
Entire Dataset: With each frame being sized with 3400 features and stored as torch.float32 (4 bytes per value), required:
Total memory = 18,482,968 × 3400 × 4 bytes ≈ 251.77GB.
Single Batch: A batch of 1024 frames required,
Memory per batch = 1024×3400×4 bytes ≈ 93 MB
By processing data in batches, I reduced memory requirements drastically - making it feasible to run on machines with limited resources.
Performance Optimization
I used PyTorch's DataLoader with these tweaks:
Multiple CPU threads for parallel data loading
GPU memory pinning for faster transfers
Shuffled training data but kept validation/test sets ordered
Here's how I set up my DataLoaders:
# Initialize `Dataloader` objects for training, validation, and testing
train_dataloader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers, pin_memory=True)
val_dataloader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True)
test_dataloader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size, shuffle=False, num_workers=num_workers, pin_memory=True)
Neural Network Architecture
Deep Learning Model
After experimenting with a few model architectures, I settled on this deep feed forward neural network:
Input layer with 6 hidden layers: 1024 → 1024 → 512 → 256 → 128 → 64 neurons
Each layer includes Linear transformation, BatchNorm, ReLU activation
Output layer: 71 neurons corresponds to the phoneme classes
flattened_input_size = 40 * (2 * k + 1) # Each audio clip has num_freqs dimension of size 40
# Initialize model
model = nn.Sequential(
nn.Linear(flattened_input_size, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 512),
nn.BatchNorm1d(512),
nn.ReLU(),
nn.Linear(512, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Linear(256, 128),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Linear(128, 64),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Linear(64, num_phonemes) # Output layer with num_phonemes = 71
)
Key choices:
Some choices I made during this process included:
Gradually decreasing layer sizes helped distill relevant features.
Adding batch normalization after each layer sped up training.
Using ReLU activations proved effective for handling speech data.
Implementing the Adam optimizer with learning rate scheduling improved convergence.
Model Performance Summary:
This model achieved:
Test Data Accuracy: 74.09%
Validation Accuracy: 73.70%
Training Accuracy: 42.53%
The lower training accuracy versus validation/test is interesting - it suggests regularization might be too aggressive in my case. I'm currently exploring ways to fine tune my model by:
Reducing dropout rates
Adjusting batch normalization momentum
Testing different learning rate schedules

Model Evaluation Summary
My analysis of 71 distinct speech sounds reveals clear patterns in how these sounds are distinguished and occasionally confused in natural speech. The confusion matrix below shows that listeners correctly identify speech sounds about 74% of the time, with most confusion occurring between similar-sounding phonemes.

Key Findings
Recognition Rate: ~74% accuracy in identifying speech sounds.
Error Patterns: Misclassifications occur mostly between similar-sounding phonemes.
Sound Separation: Distinct sounds (e.g., 'p' vs. 'ee') are rarely confused.
Predictable Errors: Confusions follow patterns based on sound similarities.
Understanding Errors
Similar Sounds: Errors mostly involve phonemes with shared acoustic features.
Sound Groups: Nasals and fricatives show consistent misclassification patterns.
Clear Distinctions: Very different sounds (e.g., 'sh' vs. 'ah') are rarely confused.
Limitations
Some sound pairs are consistently harder to distinguish.
Performance varies across sound categories.
Certain phoneme combinations show consistent confusion patterns.
Discussion
A test accuracy of 74% in distinguishing 71 phonemes reflects reasonable performance, particularly given the subtle differences in natural speech. These findings match known patterns of speech perception, where errors occur between similar sounds rather than at random. This reflects how people naturally process and distinguish speech sounds.
For more details, you can explore the complete code and implementation in my GitHub repository.
Wrapping Up
This work builds on research from CMU's deep learning lab and recent advances in audio processing. It illustrates how phoneme classification can be applied practically in real-world speech recognition tasks while highlighting areas for improvement. Overall, it underscores the importance of context in analyzing speech and provides insights for future developments in this field.
Next Steps
Now that you have an overview of phoneme classification techniques, it’s your turn! Try applying these methods on your own datasets. Experiment with different model architectures or delve into advanced techniques like Recurrent Neural Networks or transformers for even better results.
I’d love to hear about your experiences—feel free to share your progress or ask questions in the comments!
References
Deep Learning for AI, Carnegie Mellon University.
PyTorch Documentation, Data Loading and Processing. Official documentation on using utilities in PyTorch to efficiently process large datasets. https://pytorch.org/docs/stable/data.html.
Deep Learning with PyTorch, Stevens, E., Antiga, L., & Viehmann, T. (2020).
Machine learning paradigms for speech recognition: An overview. IEEE Transactions on Audio, Speech, and Language Processing, 21(5), 1060-1089, Deng, L., & Li, X. (2013).
Deep speech: Scaling up end-to-end speech recognition. arXiv preprint arXiv:1412.5567. Hannun, A., Case, C., Casper, J., Catanzaro, B., Diamos, G., Elsen, Ng, A. Y. (2014).